Cleverbot Data for Machine Learning
January 2016, by Paul Tero, Ilia Zaitsev, Rollo Carpenter of Existor Ltd
Summary
There is currently a surge in work on neural-network inspired language models. Algorithms such as word2vec and GloVe convert words into vectors, and can then mathematically solve analogies such as "London is to England as Paris is to ?". To reach peak performance, these models require massive amounts of data, like the 100 billion word Google News corpus. There is corresponding interest in using similar techniques to create a realistic conversational agent. But the conversational data needed to train these models is much thinner on the ground. The Cleverbot data set contains about 1.4 billion conversational interactions. This article describes this data set and describes our machine learning experiments on the data.
Introduction
Language models deal with word sequence probabilities. For example, after the words "what is your", a language model can compute the probability of the next word being "name" or "age" or "favourite" or something else entirely. Since the 1980s researchers have been using neural networks to create these models. Various network structures have been proposed including recurrent neural networks in 2010. Then in 2013 Tomáš Mikolov et al released the word2vec algorithm, a sophisticated and highly optimised neural network for turning words into vectors. word2vec was a watershed in the evolution of language models and has received much attention.
There is also a large body of work on turning sentences into vectors. Many approaches combine individual word vectors in various ways, or use word vectors as inputs to a neural network which learns sentence and paragraph vectors.
In early 2015 Google took this one step further and modelled entire conversations to create a chatbot. To create this chatbot, Google used a database of 5.5 million movie subtitles. Compare this to the 100 billion words of the Google News Corpus, or the 3 billion words in Wikipedia.
With this in mind, we would like to introduce the Cleverbot data set, with 1.4 billion conversational interactions and approximately 9 billion individual words. Cleverbot data is likely the largest source of machine-human conversational interaction available anywhere. What sort of structures in the data can be revealed? And could it be used to build a more intelligent conversational agent than the current Cleverbot? This article gives hints at answers to these questions.
History
Cleverbot is the algorithm and data behind the very popular websites Cleverbot, Evie and Boibot. Cleverbot's algorithm has developed in complexity over time, but the core concept was invented by Rollo Carpenter in 1982 as a conversational feedback loop. Every time the user says something, Cleverbot learns it and then chooses an optimal reply from past learning. Rollo began working on the algorithm more seriously in 1988, and it went online under the name Jabberwacky in 1996. In 2006 it was rebranded as Cleverbot and in 2007, talking on behalf of the company Existor Ltd, the avatar Evie joined Cleverbot. Both have also been released as smartphone apps.
The core of Cleverbot is a database recording every conversational interaction it has. We estimate that since starting to learn online in 1996 Cleverbot has had 7 or 8 billion total interactions. Dealing with such quantities of data is challenging. Storage and processing requirements dictate how much data can be kept and actively used at any one time.
Cleverbot is currently accumulating new data at a rate of between around 4 and 7 million interactions per day. We have kept a total of about 1.4 billion of these interactions. However, to formulate a reply Cleverbot currently uses 'only' 279 million of the interactions, about 3-4% of all the data it has ever learned. Even using this amount of data requires a lot of optimisation. To deal with this we have several fast servers with large graphics cards for GPU processing, along with and optimisations at every level of serving.
How it works
Every time a user says something to Cleverbot, Cleverbot learns it and then tries to match it against something a user has said before. Imagine the first version, created on a tiny computer with 1k of memory. At the very beginning Cleverbot starts with no data and a request for the user to type something:
Whatever the user says is saved as data. If the user says "hello", Cleverbot learns that's a good thing to say at the beginning of a conversation:
| Conversation ID | Input | Output |
|---|---|---|
| 1 | hello |
Cleverbot needs to say something, and only has one possible output, so it says that:
In this case Cleverbot learns that "how are you?" is an appropriate thing to say after "hello":
| Conversation ID | Input | Output |
|---|---|---|
| 1 | hello | |
| 1 | hello | how are you? |
Now Cleverbot tries to match the whole conversation it has had so far (hello / hello / how are you?) against all its data. It can only choose between saying "hello" and "how are you?" at this point, but soon it will have many more options:
In theory the process above will continue until Cleverbot has learned every single conversation possible. With an infinitely large database and infinitely fast lookup mechanism, it could then respond exactly as a human would in any conversational context. It would seem human, but of course... it would take an infinitely long time to get to that point, and people don't always say what you'd like them to.
Cleverbot has to manage the problem: it has to work fuzzily, finding the best solution available, given incomplete and imperfect data. It it has no simple programmed tricks used by other bots, and does not use simple keyword searches. Cleverbot doesn't even really work with words themselves. Instead a central string similarity algorithm compares whole lines against each other - millions of times over for every reply it gives. Describing that algorithm is beyond the scope of this article.
Cleverbot's answers often display a surprising degree of aptness, humanness or even apparent intelligence. Countless times it has convinced visitors that it is in fact human. Cleverbot cannot be said to possess intelligence, but rather to borrow it.
Cleverbot's processing task can be summarised as "lining up" the whole of the conversation it is having now with all those it has held in the past, finding the maximum possible number of overlapping contextual similarities.
Cleverbot today
Our websites are very popular, and the degree of user engagement is exceptional.
In the last year, combined, cleverbot.com, existor.com, eviebot.com and boibot.com have seen 69.1 million sessions from 41.8 million distinct visitors, with 2.04 billion page views/interactions, and an average of around 12 minutes per session.
So approximately 14 million man-hours have been spent interacting over the course of a year. 7.1 million of the year's sessions lasted more than 30 minutes, and many far longer. 2.8 million conversations reached their 100th interaction, 475k their 200th, and 67k their 400th. These figures are all from Google Analytics.
Engagement is so high because people in general get exactly what they want: a fun conversation that is in tune with the way they want to talk. Cleverbot talks in many languages, countless styles and on every topic under the sun. To a significant degree it reflects the person that has come to talk to it.
Sample conversations and fans
Over the years, millions of people have posted parts of their Cleverbot conversations online. This Buzzfeed article from early 2014 collects together some amusing ones, and searches will quickly reveal many more. We have curated some example conversations and have tweeted short snippets.
Cleverbot has many dedicated fans, including those who acted in and produced 'Do You Love Me', a film by Cleverbot, and live theatre in The Cleverbot Plays.
Some of the world's top YouTubers create videos of themselves talking to Cleverbot and our avatars, in many different languages, often in zany ways, including pewdiepie, squeezie and many more.
One of our favourite videos comes from the Cornell Creative Machines Lab. The video shows two avatars holding a Cleverbot-to-Cleverbot conversation. After preliminaries, they end up in a religious debate with an unusual punchline:

On a more serious note, Cleverbot has performed well in several informal Turing tests over the years. There are also descriptions of 59% human and 42% human results at cleverbot.com.
Cleverbot interfaces
The Cleverbot algorithm and data today has three main interfaces on the websites Cleverbot,
Evie and Boibot:
All employ a responsive layout so they can be easily used on a phone or tablet. They are intuitive, with a settings icon and microphone icon where supported. Evie and Boibot also feature graphical avatars with text-to-speech. Evie and Boibot start the conversation (from a random set of opening lines in about 10 languages), whereas Cleverbot waits for the user to begin as in the example above. During a conversation, communication with the server happens via AJAX with Javascript updating the interface to show the conversation history.
Languages and demographics
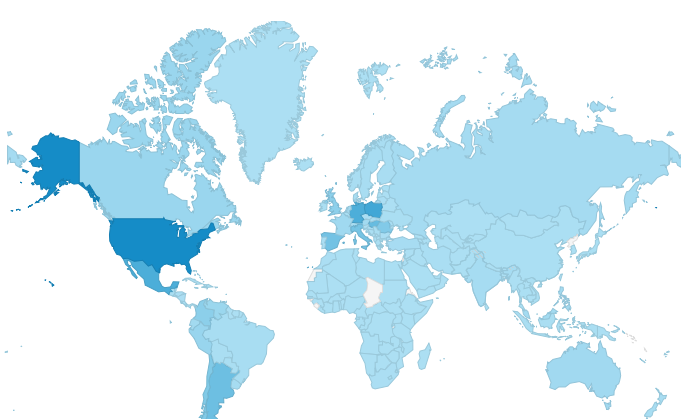
Although Cleverbot began primarily in English, it is now used all over the world. In September 2015 the most visitors came from the United States, Poland, Mexico, Germany, Hungary and Argentina:
Languages
This is also reflected in the languages spoken to Cleverbot. We have two main methods for analysing language usage. On browsers which support webkit speech (like Google Chrome) the interface shows a microphone which the user can click to enable automatic speech recognition. At the same time, they are offered a language selection which we record along with the interaction. The second method is Google Analytics. Using ASR is more accurate but applies to only a small number of users. The two methods roughly agree on results. In September 2015 the top 10 languages were as follows:
| Language | ASR language |
|---|---|
| English | 28.7% |
| Spanish | 28.6% |
| German | 8.2% |
| Italian | 7.5% |
| Romanian | 6.1% |
| Polish | 5.3% |
| Hungarian | 3.9% |
| French | 2.0% |
| Turkish | 1.0% |
This only reflects data collected in one month. It is difficult to analyse the language content of the entire data set. Most language detection routines recommend inputting tens or hundreds of words. We can detect the language over a whole conversation, though many users switch between languages. Often a conversation starts in English and changes to Spanish or German when the user realises that Cleverbot speaks their language. Based on informal language detection measurements, we suspect the full data set roughly follows the proportions above but with more English.
Unicode ranges
We can more reliably measure the Unicode ranges of Cleverbot's active (279 million row) database. These ranges are akin to alphabets. For instance, the Unicode numbers from 32 to 591 represent Latin-based characters used for writing most European languages. As of October 2015, the active database contains the following Unicode range distribution. In this table, the Greek is particularly interesting because Cleverbot only became fully UTF-8 aware in late 2014. Greek was learned virtually from scratch using the learning mechanism described above and now has nearly 40,000 rows. Russian, Japanase and Korean data was imported from separate language-specific versions of Cleverbot at around the same time and has since grown significantly.
| Unicode ranges | Number of rows (Oct 2015) | % |
|---|---|---|
| Latin | 258m | 99.22% |
| Cyrillic | 1.4m | 0.55% |
| Hirigana & Katakana (Japanese) | 314k | 0.12% |
| Hangul (Korean) | 195k | 0.08% |
| Greek | 40k | 0.02% |
| Arabic | 15k | 0.01% |
| Hebrew | 3k | 0.001% |
| CJK (Chinese logograms) | 2k | 0.001% |
| Total | 279m | 100% |
Demographics
Demographically all three websites are most popular in the 18-24 age group according to Google Analytics (September 2015). We suspect that under 18s also make up a significant proportion of our visitors as well though this is not measured in Analytics:
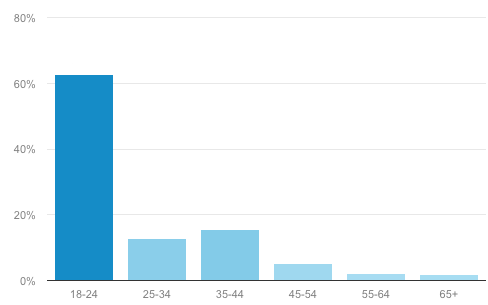
According to the graph over 60% of our users are in the 18-24 age range. Google Analytics also shows that 55% of our visitors are female and 45% male, which is perhaps the opposite of way you might expect of a bot, and shows its more social significance.
Data statistics
We mentioned that Cleverbot actively uses less data than it could due to technical practicalities. There are also social and moral considersations.
Cleverbot employs many filtering rules and patterns to determine which rows should make up the active database. The rules favour longer non-repetitive lines and conversations, and largely ban swearing and explicit sexual references so as to prevent Cleverbot from engaging in such activities. Much of the filtering consists of matches against manually curated lists of strings, which are more completely specified in English than most other languages.
With this in mind, we can present some general statistics about the Cleverbot data, with figures actual and estimated as of 2nd December 2015:
| Measure | Active data set | Unfiltered data set |
|---|---|---|
| Total data size | 279 million | 1399 million |
| Average conversation length | 33 interactions | 45 interactions |
| Estimated median conversation length | 23 interactions | 23 interactions |
Much of our active data was collected before we started storing all unfiltered data, and as a result only 6.5% of the unfiltered data exists also in the active, filtered data set. On that basis the total overall number of lines can be said to be 1587 million.
Suitability for machine learning
We have now introduced the Cleverbot data set, including how the data is collected and a brief statistical breakdown. Now we will address how suitable this data is for machine learning.
First of all, we must draw a distinction between "interactions" and "lines". Thus far all statistics have referred to conversational interactions: the bot says something and the user replies. Each row in the database represents one of these interactions.
For machine learning purposes we consider the user's side of the conversation to be nearly 100% reliable. In other words, given the context of all the previous lines, the user's response to that context is almost always a reliable human response, though we can make no claims for its intelligence. Some people swear at Cleverbot or try to chat it up, change the topic every line or type complete nonsense. But all of those are still valid human responses in the current conversational context. A very small percent may be other bots chatting with Cleverbot (or Cleverbot chatting against itself), but we have various rules in our top level servers to prevent that kind of usage or learning.
Cleverbot's side of the conversation on the other hand is a mirroring of what other users have said in the past. Usually it follows the flow of the conversation and sometimes it is strikingly good, but it can also suddenly change topics and may come across as having a poor factual memory - it forgets names and preferences.
There are therefore two approaches to using Cleverbot data for machine learning:
- Train with only the user's input, using the rest of the conversation as context for each user input
- Assume Cleverbot is relatively coherent and train using both sides of the conversation in sequence
We have run most of our own machine learning test on the data using the second method above, because it effectively doubles the size of the data set, and is much easier to work with.
Existor's machine learning experiments
In 2015 we started using modern machine learning techniques to build a new, more intelligent conversational AI. We began with unsupervised learning techniques to build a model that could capture the natural structure of our data at a line and conversation level. We were inspired by the word-level vector relationships that word2vec reveals. These include things like a capital-city relationship:
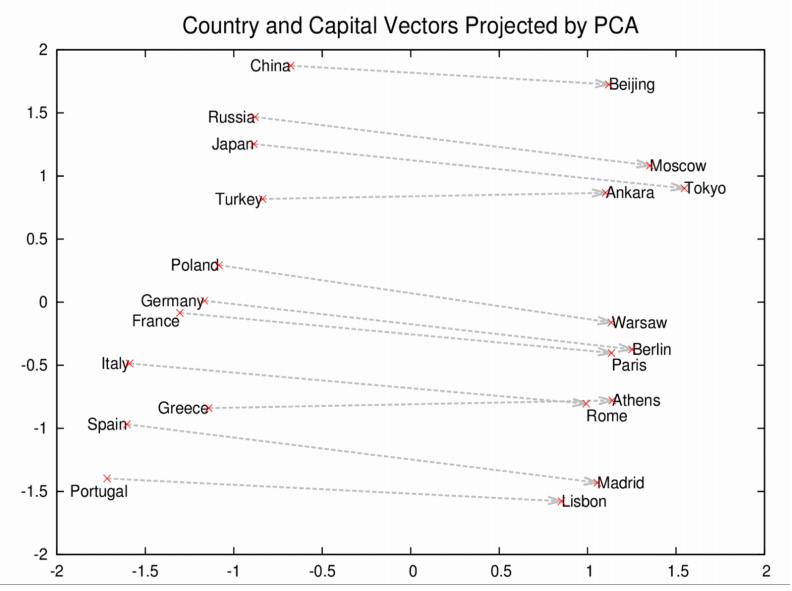
We hoped our model would encode something similar on a line-level, to show that we "shall know a line by the company it keeps". As described in the introduction, going from word vectors to line vectors (the composition problem) is an open machine learning challenge. We hoped that with sheer quantity of data, we could more-or-less bypass the issue and analyse the relationships between lines directly, without first splitting them into words. This turned out to be impractical. There are far too many unique lines. We also considered paragraph vectors but they don't work on one word lines like "Hello!", of which there are many in the Cleverbot data. Instead we used a simple composition approach, followed by clustering, to reduce the number of unique lines, and then analysed the clustered lines. All these stages are unsupervised. Our experiment was as follows:
Hypothesis
We aimed to build an efficient model of Cleverbot data in order to encode line level relationships. We hypothesised that we would discover simple question/answer and formal/informal relationships between lines. For example, we thought that the following relations would hold how old are you - 40 years old = what is your name - frank and hello - hi = how are you - what's up. To this end, we implemented the following pipeline:
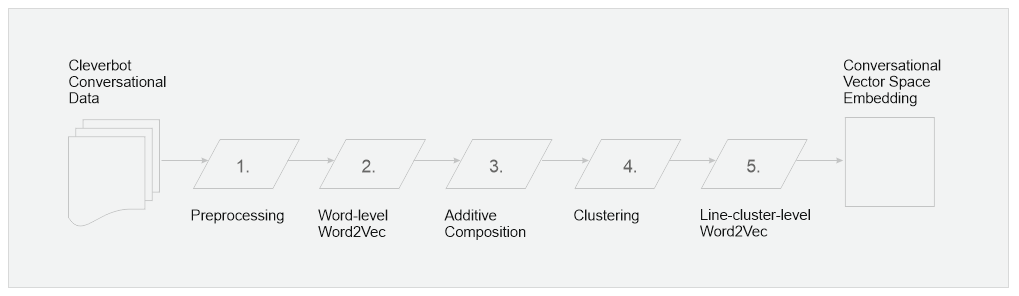
1 Preprocessing
So far we have been working with small subsets of Cleverbot's active data set. We have tested on 2 million, 20 million and 50 million lines (1, 10, and 25 million interactions) treating both the bot and user side of the conversation equally. We first extract the bot and user columns from the raw log files, lower case them, and remove punctuation. We save the output to a long text file, with each line of conversation on one line of the file. We add a line "EOC" at the end of each conversation as a marker.
2 Word2vec
We run the resulting text file through word2vec to turn all the words into 100 dimensional vectors. We use relatively low dimensions to allow the following stages to run faster. We use skip-grams with a context window of 12 (which usually encompasses the whole line as they are on average 3 words long).
3 Summation
We reprocess the text file to produce a vector for every line by summation.
4 Clustering
Then we cluster those summed (and normalised) lines. Note that this step is only to reduce the number of unique lines. For example it allows close variations of "what is your name" like "what is his name", "whats your name" to be grouped together. For lines with several words, these clusters usually contain similar words in different orders. For lines with 1 or 2 words, the clusters contain different words used in similar contexts, such as numbers (18, 21, 20) or first names (bob, paul, lisa, jenny).
To cluster, we wrote our own C implementation of Mini-batch K-means with K-means++ initialisation. In a data set of 50 million lines, there are about 24 million unique lines, and only 6 million which occur more than once. We have modified the clustering algorithm to work with unique lines plus line counts. It results in a slightly higher sum-of-squares error, but means we can run it 10 times faster. The output is a vector for each cluster. We use this to label the original text file, matching each line to its closest cluster.
Choosing the exact number of clusters is difficult, because we are not seeking to just reduce the sum-of-squares error. Rather, we want few enough to find structures, but many enough for those structures to be meaningful. In the extreme, if there is just 1 cluster, then all lines will be assigned to the same cluster and so all vector operations will equal 0 eg "what is your name" - "frank" = C1 - C1 = 0. At the other extreme, if every unique line is in its own cluster, then clustering hasn't helped at all. As determined by our testing procedure described below, we ended up with 10-30,000 clusters for 50m lines of data.
5 Word2vec again
Then we run word2vec again on the labelled lines. The vocabulary of this instance of word2vec is small as it just represents the clusters. We found the best results using the continuous bag of words method with a small number of dimensions (20-25) and small context window because we wanted our model to capture more focused information about lines.
6 Testing
We tested our vectors using a similar approach to Google, by building a file of relations we expected to find, such as frank -
However, this method suffers from the issue above with a 100% score when every line is assigned to the same single cluster. We realised this is actually a reflection of a larger issue with all word2vec calculations, where the resulting vectors is often very close to one of the operators. So the score for our pipeline was based on how well "40 years old" matched frank - what is your name + how old are you combined with how much it differred from "frank" and "how old are you". We came up with a percentage metric to represent this.
Results
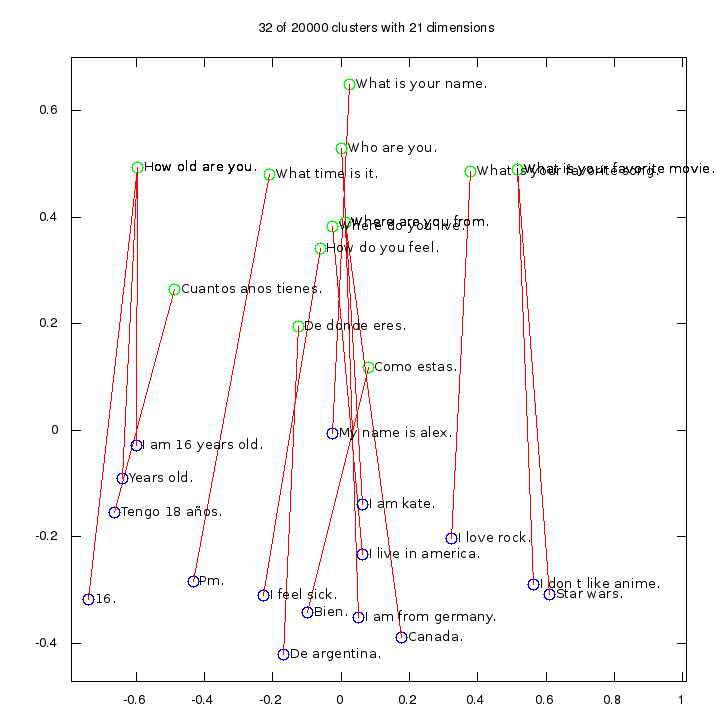
With this in mind, we found the question/answer relation we were looking for, but not formal/informal which appears much more subtle. The graph below is based on 50 million lines of data with 20,000 clusters, showing the first two dimensions after PCA. It scored 21% on our metric. To label the graph, we worked backwards from the cluster numbers (like C12) and found the most commonly occurring line near to that cluster. Note that this even includes some cross language relations like
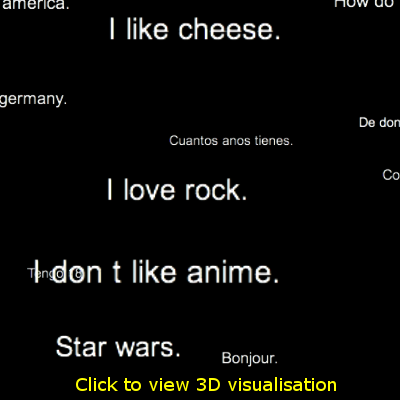
Other test sets
We ran the movie subtitle database through our pipeline as well. It scored at most 3% according to our metric. This broadly means that the question/answer relationship was not reflected in the movie subtitle data.
Analysis
This hints at the ability to build quite an efficient model of conversational data using an unsupervised pipeline. As we have shown above this model can be used as it is to answer questions by simple vector operations. We speculate that this works because conversations become represented by sequences like "greeting greeting-reply question answer question answer salutation". If a specific question/answer pair appears often enough in these contexts, the question/answer relation is encoded in the vector space. This is rather like parts-of-speech tagging but on a line level. Parts-of-speech taggers also use small context windows to extract the relationships between words and their immediate neighbours. This pipeline does something similar to lines.
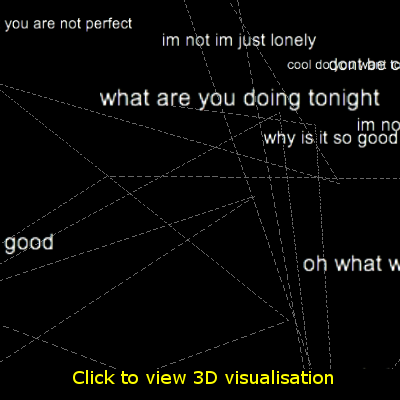
Below is a 3D visualisation that can give an intuition about the future Cleverbot "brain". To imagine a conversation you can draw a path between labels. Of course the future Cleverbot "brain" will have many hundreds of dimensions and it's very difficult to draw a line in such a high-dimensional vector space but 3D is the best we can do in our limited physical reality.
Cleverbot RNN Language Model
Our current machine learning work involves using the Cleverbot data to train a language model to generate conversational replies. This work is in its early stages, but we are already seeing some good results. The conversations below were a user talking to the language model, and the model's replies were generated word by word. We trained it with just 7.5 million rows of English Cleverbot data split into conversations, using an off-the-shelf RNN with GRUs for the activation function and a single hidden layer with 256 nodes. Each separate conversation was considered as a single sequence, with a beginning-of-conversation marker and end-of-line markers between lines. The vocabulary size was around 200,000 words. We did no programming of our own for this - just using available tools and optimising different parameters.
User: do you have something to say?
RNN: yes.
User: what shall we talk about?
RNN: who are you?
User: i am me. are you anybody?
RNN: i am.
User: but you are not real.
RNN: yes i am.
User: you are a rnn.
RNN: no i'm not.
Of greater significance than any one RNN reply is to look at the first few results, given a conversational context such as at the point of the last reply above. Possible alternative replies reveal contextual relevance, as well as good sentence construction:
-2.125913 no i'm not.
-3.138643 my name is cleverbot.
-3.743327 i don't think so.
-4.362488 you are very clever.
(The number represents the probability of each sequence of words.) A further example conversation:
User: how are you today?
RNN: good.
User: does life have meaning to you?
RNN: sometimes.
User: give me an example.
RNN: example of what?
User: of life the universe or anything.
RNN: me.
And the top few results in that context:
-3.623500 me.
-4.385503 no?
-4.981720 i'll never know.
-5.380015 atheist.
Conclusion
At the beginning of this article, we referred to the 100 billion word Google News Corpus data set and the 3 billion word Wikipedia dump, and stated that we believe the Cleverbot corpus is the largest data set of its kind. The Cleverbot corpus contains approximately 1.4 billion interactions, increasing by millions per day. If both sides of the conversation are used, there are about 3 billion lines of conversation to analyse.
We then asked the following questions, and will now try to answer them.
What sort of structures can be revealed in the Cleverbot corpus?
We have given a brief demonstration above of the sorts of structures which may be contained within the Cleverbot data set. That research is based on about 5 man-months of investigation, using existing tools and existing ideas. And it does suggest that line-level structure exists. With more time and resources, this hint can be built upon. So an initial answer is "line-level relationships can be revealed".
And could it be used to build a more intelligent conversational agent?
We think so, and we are currently attempting to build a new version of Cleverbot using machine learning techniques.
For more information
Please email us at if you are interested in further information on the Cleverbot corpus or our machine learning software, past and future.