Machine Learning
As of April 2016, the Cleverbot data set contains over 2 billion conversational interactions. We have launched several machine learning projects to analyse and mine this data. Some of these projects are described below.
Analogies and Intelligence
We consider analogy a key aspect of intelligence, and have made significant recent progress towards creating a new ML model of analogy in language.
Line Vectors Using Cleverbot Data
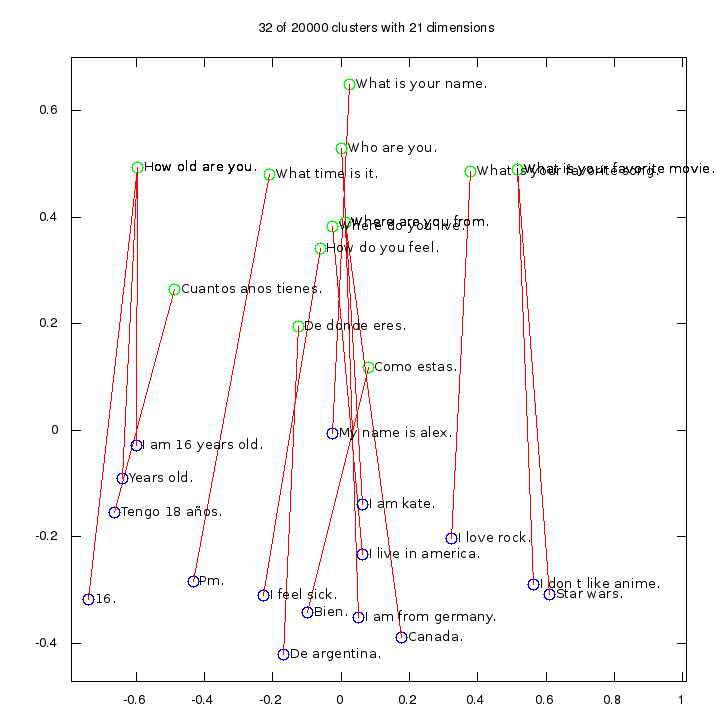
Our first machine learning project in mid 2015 looked for line-level structures in the Cleverbot data, hoping to imitate the success of word2vec. Please read the full description in our Cleverbot data article to find out how we did.